DOAI:DOI→オープンアクセス文献へナビゲートするサービス
先日訪問したビーレフェルト大学@ドイツでは「BASE(Bielefeld Academic Search Engine)」というオープンアクセス文献の検索エンジンについても話を聞いてきました。
BASEについては2010年にカレントアウェアネス-Rで紹介されていますし、うちのJEEPwayというサービスのなかでデータソースのひとつとして使っていることもあり、それなりの知識は持っていました。
DOAI
最近、そんなBASEをベースにしたDOAI(Digital Open Access Identifier)というおもしろげなサービスが出たそうです。
どんなサービスかというのは、
http://doai.io/10.1016/j.jalgebra.2015.09.023 vs
http://dx.doi.org/10.1016/j.jalgebra.2015.09.023
という例を見れば一目瞭然で。つまり、DOIを通常の dx.doi.org ではなく doai.io でリゾルブするだけで、そのDOIの文献の“オープンアクセス版”へとナビゲートしてもらえるというものです(例ではarXivやResearchGateにデポジットされた文献が表示される)。
マルチプルレゾリューションとの比較
複数のサイトで“同一”のコンテンツが公開されている場合に、両者に対して同じDOIを登録することでマルチプルレゾリューションを行うことがあります。
マルチプルレゾリューションというのは耳慣れないと思いますが、以下のリンクをクリックしていただくとどういうものか想像していただけるかと。
例)http://doi.org/10.11501/3185363
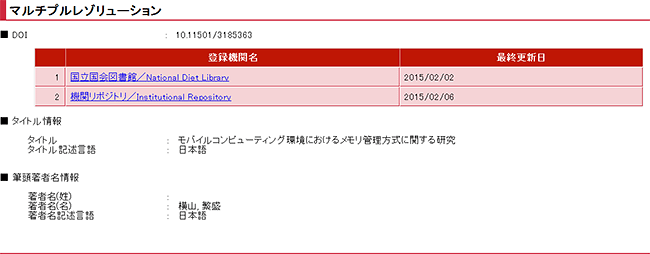
この例は、国立国会図書館(NDL)でデジタル化した博士論文(NDLでDOIを採番)のPDFを、静岡大学の機関リポジトリでも公開して、NDLの付与したDOIをメタデータに登録している、という(よくある)ケースです。逆に、大学側が先に機関リポジトリで博士論文を公開し、DOIを採番し、そのメタデータがまわりまわってNDLに到着し、大学の付与したDOIをメタデータに登録する、というかたちでのマルチプルレゾリューションもあります。前者のパターンではNDL>大学の順、後者では大学>NDLの順でリンクが表示されると思います。DOIを採番したほうが上に来るということですね。
こんな「中間窓」を使ったナビゲーションを、“同一”のコンテンツに対してだけではなく、“異なる版”(ここでは、内容はほぼ同一だが形式が違うものと理解してください。いわゆる出版社版と著者最終稿の関係など)のコンテンツに対しても行うことができれば……というのを考えたことがあります。でもCrossRefに(中略)で、実現可能性は低いだろうなあと。
そんなわけで、この、なんというかDOIのリゾルバーを乗っ取ってしまうというような発想にびっくりしました。シンプルでパワフル。もちろんそれを支えているのはBASEというデータベースであり、そこに収録されたオープンアクセス文献のメタデータに(どこかのだれかが)出版社版のDOIをしっかり記述したこと、です。
現在のDOAIはストレートにオープンアクセス文献のほうへナビゲートしてくれるようですが、マルチプルレゾリューションのような中間窓を表示し、その中で、オリジナルの論文へのリンクも表示するようにしてくれたら利便性があがりますね(doi.orgでリンクするだけなので実現は簡単)。そうしたら、図書館のサービスのなかでDOIを使ったリンクを書くときは常に doai.io を使えばよくなります。
まあこういうのは本来リンクリゾルバの役割なのかもしれません。ただ、OpenURLは汚いですからね……。それはともかく(ビーレフェルト大学でBASEがEBSCO Discovery Serviceに収録されたという話を聞いたので)EBSCOさんにDOAIのことをお知らせしたところ、EBSCOのリンクリゾルバでリンクアウト先に加えてみたという反応がさくっと返ってきたりもしました。
Hybrid Bookshelf at Universitätsbibliothek Konstanz
http://www.hybridbookshelf.de/
http://www.kn.bibshelf.de/
ちょいネタですが、海外出張先からブログを更新してみるのも乙かなと思い。
ドイツ南端に位置しスイスと国境を接しているコンスタンツという湖畔の街に来ています。日本との時差は8時間。今朝は雪でした。国内有数の観光地ということもあってか先に訪れたビーレフェルトやゲッティンゲンに比べると格段に落書きが少ないのですが、ドイツ鉄道(DB)の駅のすぐ横にスポーツ用品のアウトレットがあり、その真向かいにスポーツ用品店があり、さらにその南側のショッピングセンターにもスポーツ用品店があり、となんだかノリがよく分かりません。
さて。駅前から9番線のバス(もちろんメルセデス製)で10分ほど山のほうへ登っていったところに、コンスタンツ大学というドイツのExzellenzinitiative(Excellence Initiative)にも選ばれているエリート大学があります。その図書館でちらっと見かけたシステムが面白かったので動画に撮ってみました。
ブラウジングのためのツールですね。さくさく動いています。2009年に中国出張に行ったときにも同じようなものを見たけれど、もうちょっと洗練された印象を受けました。(なお、動画中で「おお、リンクリゾルバ」と言っているのはわたしです。)
同行者にはこんなの自力で開発するわけないからなんかのクラウドサービスを利用しているんだろうと言ったのですが、それは半分当たっていて半分間違っていたようで、Hybrid Bookshelfというサービスを利用しているものの、その開発にはコンスタンツ大学自身が関わっていたらしい。フロントエンドの開発自体はpicibirdという会社が担当しているようです。
以下は館内写真。耳栓(1ユーロ)のガチャガチャが斬新でした。なお、地理的に図書館が大学の中心に位置しているというのが今回の調査結果のキーポイントだったのですがそれについてはまた別の機会に……。







How Metadata Quality is assessed in Europeana(Europeanaの報告書より)
http://pro.europeana.eu/files/Europeana_Professional/Publications/Metadata%20Quality%20Report.pdf
Europeanaのメタデータマネジメントの実態が垣間見える“Report and Recommendations from the Task Force on Metadata Quality”(2015年5月)という報告書をざっと読んだ。
図書館界隈でもウェブ上に分散するシステムからメタデータをアグリゲートして大規模なデータベースを構築するという例は少なくない。そういったシステムにおいてはしばしば汚いメタデータと格闘するはめになる(はずだ)が、その実態を知る機会は少ないのでこの報告書はとてもありがたい。特に多言語環境のメタデータマネジメントの苦労は気になるところだった。
報告書の概要はカレントアウェアネス-Eで阿部さんがみごとに紹介されている(これまたありがたい)。ただ、原文を読んでみたらいろいろ面白い(自分好みの)情報が書かれていたので、特に私が強く興味を持った“How Metadata Quality is assessed in Europeana”というセクションについてメモしておきたい。
疎外感
いきなり
Members of the Task Force, and data partners contributing to the Europeana Aggregators’ Forum, raised issues of feeling excluded from Europeana. They felt that they did not understand what happened to their data once it left their own repositories.
という出だしに思わず笑ってしまった。そう。疎外感がある。
EDM(Europeana Data Model)における9個の必須要素
Fig 2.1.1に挙げられている要素は以下の通り。9個じゃなく10個あるけど最後のは「あれば必須」。
- edm:dataProvider
- edm:isShowAt or edm:isShownBy
- edm:provider
- edm:rights
- edm:aggregatedCHO
- dc:title or dc:description
- dc:language for text objects
- dc:subject or dc:type or dc:coverage or dcterms:spatial
- edm:type
- edm:ugc (when applicable)
最低限これだけはということで定められているようだけど、“In practice, the mandatory elements are sometimes misinterpreted, accidentally misused or contradictory. ”ということらしい。
EDMについてはこちらを参照。CHO = Cultural Heritage Object、か。aggragatedはOAI-OREにちなんでいる。
http://pro.europeana.eu/page/edm-documentation
Europeana Publishing Guideというガイドラインがあるらしい。
http://pro.europeana.eu/publication/publication-policy
Europeana Aggregation teamによるメタデータチェック
体制
人手によるチェック。まず気になるのは担当者の人数(FTE)とエフォート率。
The ingestion procedure is undertaken by a team of four Operations Officers who manually process all datasets submitted by data providers to Europeana. There is usually a period of two weeks during the month during which EDM datasets are harvested, assessed, edited and enriched to be published on the Europeana portal and API.
ワークフロー
基本的なフローは阿部さんの記事にあるとおりなので省略。プレチェック→マッピング→必須要素チェック→重複除去、の流れ。
・データセットから抽出したサンプルをEDM XMLの生データで確認する。
・フィールドの出現回数や一意のデータの数など,メタデータの統計を確認する。
・品質評価ツールMINTを使って,各フィールドの種別とその記述内容が合致している かを確認する。
・EDMスキーマへのマッピングを確認する。
・識別子に重複があるレコードを確認し削除する。
http://current.ndl.go.jp/e1688
ツール
このフローのなかで登場するのが
- SugarCRM:データプロバイダの管理
- REPOX:OAI-PMHハーベスタ
- UIM (Unified Ingestion Manager):メタデータのインポート、デリファレンス、エンリッチメント
- MINT:クオリティチェック、マッピング、修正、変換、ヴァリデーション
というツールたち。
最初のSugarCRMは本当はメタデータチェックとは関係ないんだけど、なるほど、ここでCRMツールを使うんだ、と驚いた。図書館利用者への問い合わせ対応をCRMで、履歴を全学で共有して、ってのはむかし考えてたけど……。
残るREPOX、UIM、MINTの3つがメインのツールになる。このうちMINTが一番重要。なお、REPOXとMINTはD-NET(OpenAIREのインフラ)でも使われていると別の文献で読んだ。
http://dx.doi.org/10.1108/PROG-08-2013-0045
統計を確認?
上の2番目の「メタデータの統計を確認する」はことばだけだとちょっと分かりづらい。例えばMINTではデータセットのざっくりした感じをつかめるようで、例えば以下の図は @rdf:about が258494件あるけど、ユニーク(distinct)な dc:title は61169件、dc:description は11件しかない、なんかやばい、という例を示したもの。

その他に edm:isShownAt や edm:isShownBy に記述されたリンクをチェックしたり、外部のシソーラス(Getty Art and Architecture Thesaurus等)へのリンクが適切かどうかをチェックしたり(ここでUIMがシソーラスのデータを引っ張ってきて表示してくれる。これがデリファレンスだろう)。

重複除去
最後に重複除去。これはMINTではなくUIMのほうで行うらしい。
This only occurs when the identifiers (rdf:about of the edm:ProvidedCHO) are duplicates or near duplicates in the dataset. Unfortunately, it does not apply duplication checks to all metadata 39/54 Report and Recommendations from the Europeana Task Force on Metadata Quality fields and so cannot identify multiple records containing the same titles or descriptions.
isVersionOfとhasVersionの違い
単なる疑問メモ。dcterms:isVersionOf(~の異版である)と、dcterms:hasVersion(~を異版に持つ)の違いがよく分からない。
DCのサイトには以下のようにある。
http://dublincore.org/documents/dcmi-terms/
- isVersionOf: A related resource of which the described resource is a version, edition, or adaptation.
- hasVersion: A related resource that is a version, edition, or adaptation of the described resource.
この説明だと両要素の関係はシンメトリックに見えるので、何か版違いのAとBがあったときに
- A isVersionOf B
- A hasVersion B
のどちらを使ったらいいのかが分からない。
似たような要素にisFormatOfとhasFormatがあるんだけど、こちらは時系列によって主従関係が決められているので分かりやすい。
- isFormatOf: A related resource that is substantially the same as the described resource, but in another format.
- hasFormat: A related resource that is substantially the same as the pre-existing described resource, but in another format.
Versionの場合、何かしら「正版」というものがあるということが念頭に置かれているのだろうか。それって誰がどうやって決めてるんだろうか。(あるローカルな系でルールを決めてそれを徹底するのは可能だろうけど、あまたからアグリゲートしてうんぬんとやったときに一貫性が保てるとは思えない。)
仮にFormatのように時系列に従うなら分かりやすいんだけど、機関リポジトリでは定番の著者最終稿(author manuscript)/出版社版(publisher version)の関係を記述する場合には
- 著者最終稿 hasVersion 出版社版
- 出版社版 isVersionOf 著者最終稿
となるはずで、出版社版が「異版」として扱うことになるのは気持ちが悪い。
ビーレフェルト大学とOpenAIREの関わり
http://www.ub.uni-bielefeld.de/english/
申し訳ないことにビーレフェルトという大学にあんまり強い印象を持ってなくて、ここがOpenAIREのテクニカルなインフラにおいて重要な役割を担っていると言われてもいまいちピンと来てなかった。ドイツでテクニカルな話題と言って頭に浮かぶのは、TIB、KIT、MPDL、とかだったので。
が、以下のくだりを読んでいろいろと断片的な知識がつながり、すとんと腑に落ちた。というか、単に自分が無知だっただけであることが分かった。
The main areas of expertise to be contributed to OpenAIRE is resulting from the work on information infrastructures, specifically on aggregating and networking high numbers of open document repositories[.] The search engine BASE, for example, aggregates since 5 years distributed repositories, by providing access to about 20 Mio. publications from 1200 international sources (March 2009). Further contributions concern the linking of repositories to CRIS systems (in the context of Knowledge Exchange) and usage data (in the context of PEER). Since Bielefeld University Library is responsible for general data management aspects in OpenAIRE, it will also lead the studies on subject-specific requirements for primary and secondary research data.
ひとつめのBASEはオープンアクセス論文のデータベース。この開発・運営を通してアグリゲーションのノウハウを貯めたんだろうか(あるいはDRIVERでの経験が先なのだろうか)。BASEのはなしはついでかと感じていたけど、重要な調査テーマに格上げしないと。
http://www.base-search.net/
リポジトリ→CRISのリンク。Knowledge ExchangeがかつてCRIS OAR Interoperability Projectというプロジェクトをやっていたのは知っていたけど、ここにビーレフェルト大学が絡んでいたことまでは押さえてなかった。(KEのサイトからはページが消えてしまっているのでwayback)
https://web.archive.org/web/20120720092939/http://www.knowledge-exchange.info/Default.aspx?ID=340
http://www.ukoln.ac.uk/rim/projects/cris-oar/
https://infoshare.dtv.dk/twiki/pub/KeCrisOar/ProjectDocuments/Knowledge_Exchange_CRIS-OAR_final_report_26032012.pdf
PEER(E1234、E1318参照)プロジェクトのfinal reportを見てみると次のようにある。てっきりPEER Depotの開発担当かと思ったら、そっちはフランスのInriaだったらしい。ここで引き合いにされるのはusage dataのほうなのか。
3.7 Bielefeld University Library:
Bielefeld University has contributed significantly to shape the German landscape of digital research libraries and electronic information and is heavily involved in international initiatives for research infrastructures for processing digital information.
Role in PEER: Bielefeld University provided the technical interfaces to DRIVER and to repository networks and aggregations. UniBi is a full technical partner in DRIVER and DRIVER-II and specializes in the aggregation aspect of distributed document repositories. Through this expertise and 5 years of experience operating the scientific search engine BASE which predominantly builds on repository contents, UniBi facilitated the implementation of the required repository interfaces for the PEER project.
http://www.peerproject.eu/fileadmin/media/reports/20120618_PEER_Final_public_report_D9-13.pdf
というわけで超重要機関だった。
教訓として、こういう大規模プロジェクトでどの機関がどのような役割を担ったのかという知識をきっちり入れておく(ないしsearchableにしておく)と後々役に立つ。